From Copilot to Local AI: Running LLMs for Code

Development
LLMs are now being used everywhere. While ChatGPT is mainly used for creating texts and Midjourney for generating images, there are also LLMs that are meant to assist developers.
GitHub's Copilot is probably the most well-known. There are now integrations for almost all popular IDEs and code editors. Copilot functions like an autocomplete tool, but instead of just suggesting methods, it can suggest entire blocks of code.
With targeted guidance, code can often be written faster. However, don't expect miracles (yet). Nonetheless, I find such assistance to be practical. However, it's not exactly cheap.
Depending on the provider, you have to budget at least $10 per month. And then there's the dependency on the provider, which I, personally, find problematic. It would be much better to have your own assistant running on your machine. But is that even possible?
Fortunately, yes. I’ll explain how.
In the following text, I'll refer to a Mac installation, but the process also works on Linux and Windows, though you might need to use different apps.
Ollama
Our setup is based on two important components. On the one hand, we need a model that does the actual work, and on the other hand, we need something for this model to run on.
The easiest way to get a model running is Ollama. Ollama is available for Mac, Linux, and (with limitations) for Windows. Ollama is open source and can be used for free. If you would rather not install Ollama directly, you can also use a Docker image.
With or without Docker, to run a model somewhat effectively, we require a computer with enough processing power. A Mac with an M processor is a must.
The installation is simple: just download and run the installer.
Subsequently, Ollama runs, but you will search in vain for a graphical interface. We will initially control Ollama via the terminal; later, we can install a GUI.
Model
The next step is to install a model. There are numerous models to choose from, many specializing in specific tasks. We'll start with a general approach and install the currently strongest model: llama3.1.
Llama3.1 is provided by Meta and is available with varying numbers of parameters. These different sizes not only reflect the models' sizes but also the performance required to run them.
On the Ollama site, it's noted:
You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
Llama3.1 comes with 8B, 70B, and 405B parameters. It quickly becomes clear why we need a well-equipped machine to work effectively with it. Which variant you pick is up to you; I'll go with the smallest.
Installation
Now we switch to the terminal and install the appropriate model.
ollama run llama3.1This automatically installs the smallest variant, but other variants can be installed similarly; you can learn more here.
After the download is complete, we are greeted by a prompt:
We can now simply start typing and ask a question or task:
We have successfully set up an LLM locally and can now write prompts and even assign programming tasks:
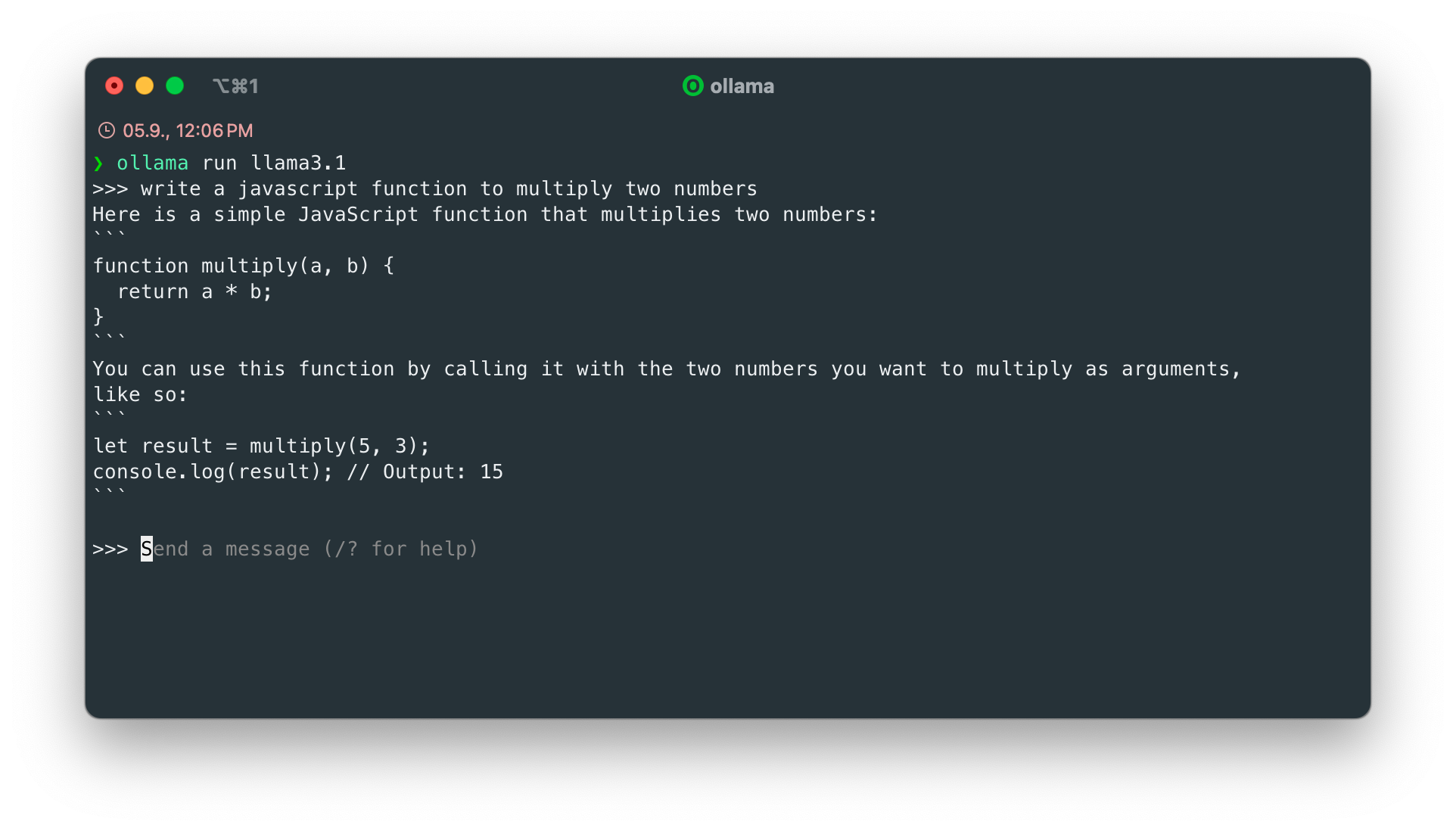
Of course, we don't want to work in the terminal all the time; we want to work directly in our IDE. To do this, we need to connect it to Ollama.
IDE
At konzentrik, we currently mainly use WebStorm by JetBrains. For my own projects, I’ve been testing Zed for some time now and am very impressed by it. Zed is a practical alternative to vscode and, thanks to Rust, doesn’t run as an Electron app:
Zed is a next-generation code editor designed for high-performance collaboration with humans and AI.
Zed
Zed already can integrate LLMs, making the integration of Ollama straightforward. To set up Ollama, we enter the following in the Command Palette (cmd+shift+p):
assistant: show configurationA new tab opens, and we can begin the configuration. Zed supports various integrations, primarily its own, but also Ollama. We find the relevant configuration in the list, and in the best case, Zed has already detected and connected Ollama!
At this point, we can also open a new context, which opens another tab. In the upper-right corner, we can now choose the desired model:
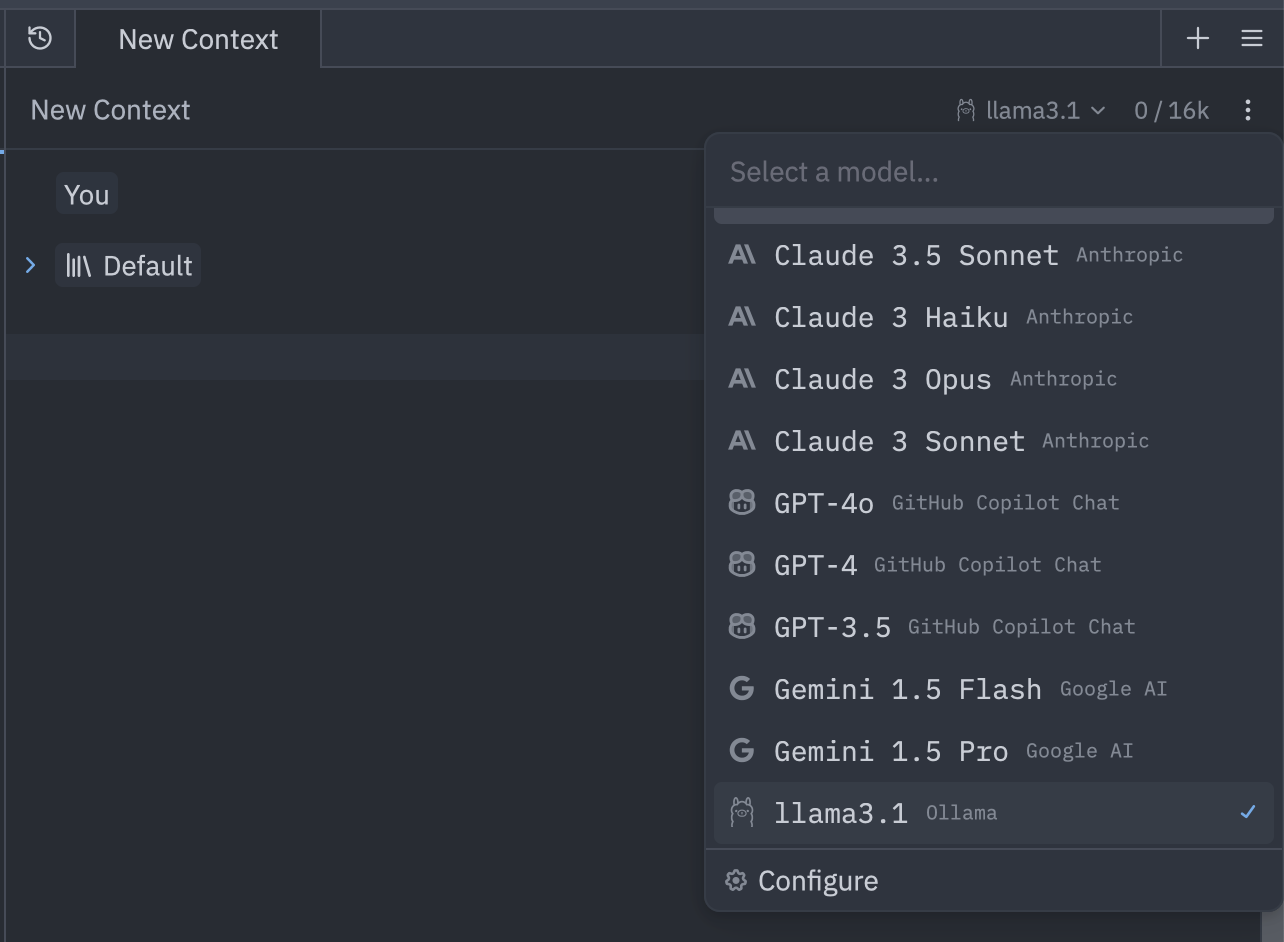
And we're ready to go! We can now give instructions, as we did in the terminal, and send them off with cmd+enter:
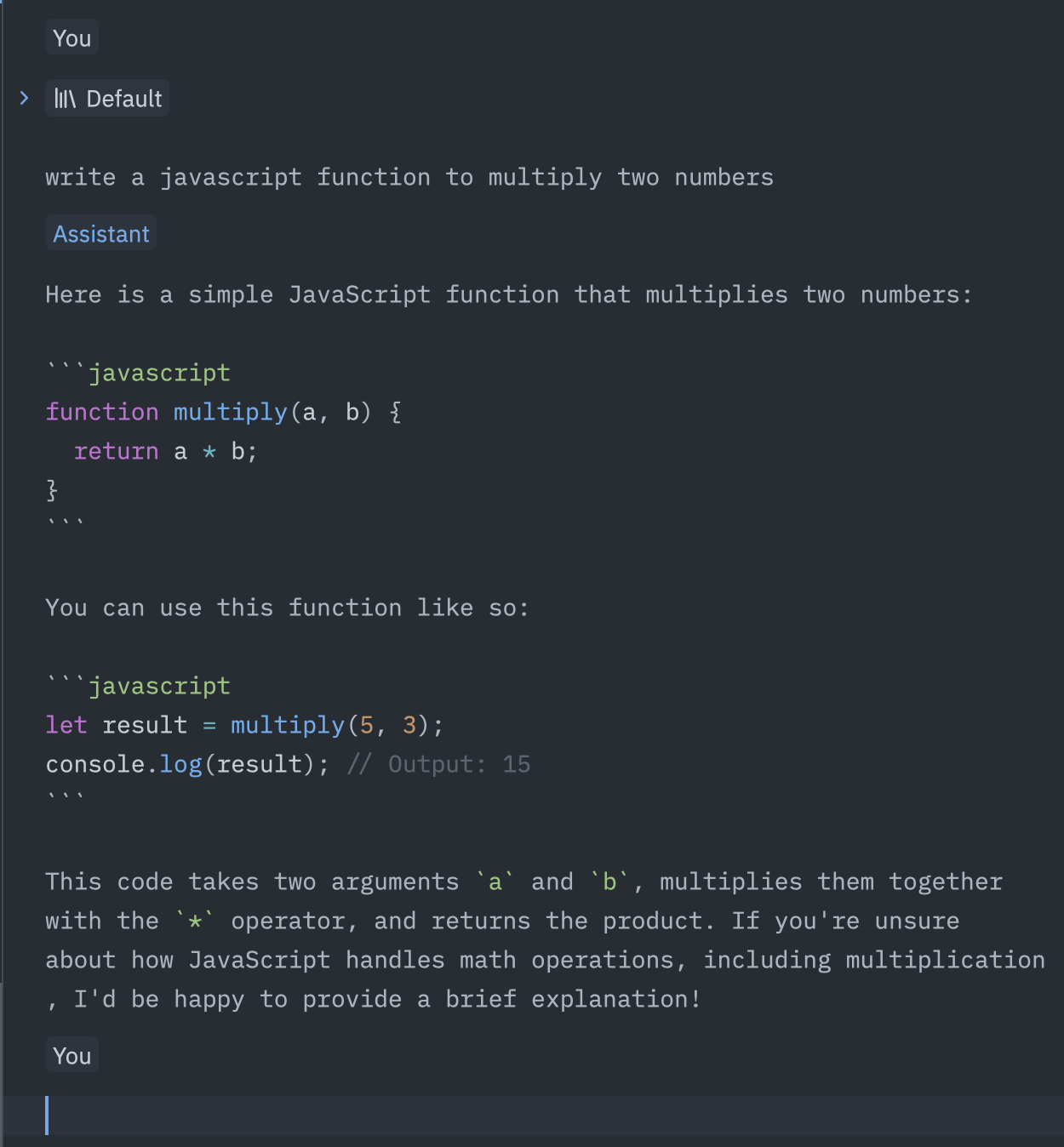
The result is the same, but thanks to Zed, we also get nice code highlighting.
However, we don’t just want to chat; we are keen to work with real code. Here, the shortcut cmd+> is helpful. It sends a marked code section to the active context:

But even when writing code, our LLM helps us out. Suggestions for possible code appear as we type. Additionally, we can use the shortcut control+enter to enter prompts directly in the code:
Perfect! This makes work much easier.
VSCode and JetBrains
If you're using VSCode or one of JetBrains' IDEs (WebStorm, PHPStorm, etc.), you'll need to install an additional plugin. Continue is a good option here.
After installation, a new panel will be available, allowing you to start a chat. You can also access the config.json in this panel, where you can configure which models should be used. More details can be found in this blog post.
Finetuning
Of course, Llama is a very general model that may not be the best choice for every application. It can therefore be useful to look at other models and do some testing. A list of supported models can be found here.
Moreover, we can also create our own model and give it specific instructions. To accomplish this, we create a model file, which is a simple text file, and we can get creative there:
FROM llama3.1
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# set the system message
SYSTEM """
You are a JavaScript developer. You write slim and clean code. Answer with code only, no explanations.
"""As you can see, our model will be based on Llama3.1, and we’ve given our model specific instructions.
We can now build and use the model directly:
ollama create jsDev -f ./Modelfile
ollama run jsDevI won't go into further detail here because this is a field of study in itself. However, this gives you a starting point for tuning your model. By the way, Continue learns from your code and stores this learned information locally. This can then be used to create even more tailored models.
GUIs
If you don’t want to use Ollama only in your IDE or terminal, you can turn to numerous interfaces. These range from web interfaces running in Docker to standalone apps. Personally, I prefer Msty. Msty makes it easy to access your own data, such as asking questions related to your own Obsidian Vault—all offline.
Conclusion
The installation and use of local LLMs has become incredibly simple. It requires a well-equipped computer, but most of us already have that for development.
By integrating the model into IDEs, it can make our lives a bit easier—provided we keep in mind that the generated code must always be reviewed with a sharp eye.
Thanks to the tools we've employed, we can even work offline and remain independent of external services.
It will be interesting to see how this technology continues to develop, what leaps will happen next, and at what point we’ll essentially become code reviewers and architects. Exciting yet questionable times lie ahead.